Low-rank matrix approximations
Prev: how-pca-works Next: tensor-methods
What are the Missing Entries?
Consider this matrix:
It would be unfair to ask what the missing numbers would be. They could be anything. But if it has nice structure, more specifically, all rows are multiples of each other, then you can fill in the blanks.
Once you know something about the structure of a partially known matrix, it’s possible to recover all of the lost information.
Matrix Rank
Rank-0 Matrices: There is only one rank-zero matrix, the all-zero matrix.
Rank-1 Matrices: A non-zero matrix where all rows are multiples of each other.
![]()
Rank-2 Matrices: A rank-two matrix is a superposition of two rank-1 matrices.
![]()
As well, any matrix A of rank k can be decomposed into a long and skinny matrix times a short and long one.
![]()
Rank-k Matrices:
Thus, a matrix A has rank k if it can be written as the sum of k rank-one matrices, and cannot be written as the sum of k - 1 or fewer rank-one matrices.
Low-Rank Matrix Approximations: Motivation
Some applications of approximating matrices, doing a low-rank approximation are:
-
Compression: The uncompressed matrix A is described by numbers, whereas the compressed version that describes Y and requires only numbers. When is small relative to and , replacing the product of and has large savings. For an image, where and are in the 10000s, a modest value of , like 100 or 150 can achieve approximations thata re good enough.
-
De-noising: If A is a noisy version of a “ground truth” signal that is approximately low-rank, then using a low-rank approximation of A might be more informative than the original.
-
Matrix completion: Low-rank approximations are a good first step to fill in missing data. TO figure out what these default values should be requires trial and error, but may include filling with 0, the average of known entries in the same row or column, and the average of entries in the matrix, or to compute the best rank-k approximation to A. This works reasonably well when the unknown matrix is close to a rank-k matrix and there are not too many missing entries.
Matrix completions can be done with the Singular Value Decomposition, the SVD, which does the following:
- express A as a list of ingredients, ordered by importance.
- keep only the k most important ingredients.
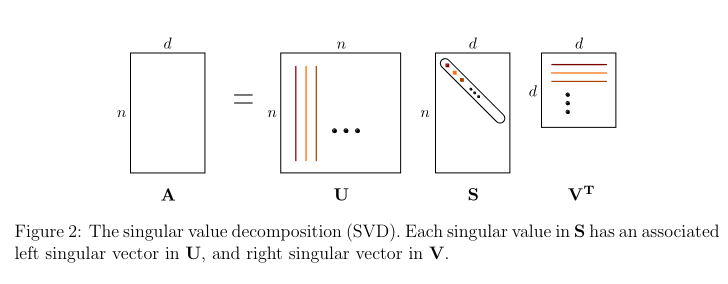
The Singular Value Decomposition (SVD)
The SVD defines an matrix A as the product of three simple matrices:
where:
- U is an orthogonal matrix.
- V is an orthogonal matrix;
- S is an diagonal matrix with nonnegative entries, with the diagonal entries sorted from high to low.
U and V are not the same, due to A not needing to be square.
The columns of U are called the left singular vectors of A, and the columns of V are the right singular vectors of A. The entries of S are the singular values of A.
The factorization of is equivalent to the expression:
where is the ith singular value and are the left and right singular vectors. Thus, SVD expresses A as a nonnegative linear combination of rank-1 matrices.
Every matrix A has a SVD. If you think of an matrix as a mapping from to , then every matrix, is only performing a rotation in the domain (a multiplication by ), then a scaling + adding or subtracting dimensions (multiplication by S), followed by a rotation in the range (multiplication by U).
The SVD of a matrix A takes time, and to compute the largest singular values, takes time.
Low-Rank Approximations from the SVD
Since the SVD reduces to the k rank-1 matrices that sum up to the original matrix, we can just keep the top K parts!
![]()
This would result in:
In more detail, this looks like this:
-
Compute the SVD where U is an orthogonal matrix, S is a nonnegative diagonal matrix with diagonal entries sorted from high to low, and is an orthogonal matrix.
-
Keep the top right singular vectors: set equal to the first k rows of .
-
Keep only the top left singular vectors: set equal to the first k rows of .
-
Keep only the top k singular values: set equal to the first k rows and columns of S, corresponding to the largest singular values of A.
-
The rank-k approximation becomes:
This only requires space to store the matrix, in contrast to space normally required.
Basically, is the concepts, where express the signal strengths of the concepts, and the rows of and columns of express the canonical row/column with each concept.
This is optimal.
For every matrix A rank target and rank-k matrix B:
Remark (How to choose k): In a perfect world it’s pretty easy to choose . The eye test works out. But you can choose some domain specific value that the top singular values is at least times as big as the sum of the other singular values, where is something like 10.
Remark (Lossy Compression via Truncated Decompositions): If your data is similar to an approximated low-rank matrix with nice structure, you can pick some low-rank approximation, throw away the rest of the data, and use that instead.
PCA Reduces to SVD
PCA reduces to SVD, without forming .
More on PCA vs. SVD
PCA is close to SVD. PCA is a data analysis approach, the best way to approximate data points as linear combinations of a small set of vectors. But the SVD works on all matrices.
The SVD does have an advantage: it returns U, which gives information on the columns as well as the rows. PCA only gives information on the rows.
-
Imagine a matrix X, where the rows are customers and the columns are the products they buy. By interpreting both the rows and columns, you can predict both the products bought but also the customer types.
-
Imagine a matrix of drug interactions, where the rows are indexed by proteins or pathways, and the columns by drugs. It’s useful to see both how proteins and drugs interact.
Prev: how-pca-works Next: tensor-methods