Property-preserving lossy compression
Prev: introduction-consistent-hashing Next: similarity-search
Heavy Hitters
Imagine that given an array of length , find an item that is a majority element, that is, appears times. One way to do this is to compute the median of , which will always be the majority element.
However, we can do better with only one pass.
counter := 0, current := NULL
for i = 1 to n:
if counter = 0:
current := A[i]
counter++
else if A[i] = current:
counter++
else:
counter--
return current
To prove that this always works, you could say that there must be items that are non-majority, and items that are majority. If we sum up the occurrences of the non-majority elements as -1, and the majority elements as 1, you would always get a positive sum (since there is always at least one more majority item).
The Heavy Hitters Problem
In the heavy hitters problem, the input is an array of length , and also a parameter . Assume . The goal is to compute the values that occur in the array at least times. There can be up to such values.
This has a lot of applications, including:
- Computing popular products (e.g. on Amazon)
- Computing frequent search queries (e.g. on Google)
- Identifying heavy TCP flows (e.g. to determine denial of service attacks)
- Identifying volatile stocks. (e.g. options volume)
Of course, to find out which items appear , we could sort the array and output a result only if it appears consequentively at least times.
An Impossibility Result
There is no algorithm that solves the Heavy Hitters problem in one pass while using a sublinear amount of auxiliary space.
This is provable because if , then we can assume that , so we would need memory to hold the possible unique items (due to the pigeonhole principle). Thus, as long as is not on the order of , heavy hitters reduces to the set membership problem, . Thus, we need at least memory, or in this case, memory to solve the generalized heavy hitters problem.
The Approximate Heavy Hitters
Let’s solve the approximate Heavy Hitters problem, where the input is an array of length , and user-defined parameters and , where:
- Every value that occurs at least times in is in the list.
- Every value in the list occurs at least times in A.
Suppose we set . Thus, the algorithm outputs every value with frequent count at least , and only values with frequency count at least . This has a space usage of , which is fine.
The Count-Min Sketch
The Count-Min Sketch has been used widely, and is a hash-based algorithm that is similar to “lossy compression”. It throws away most of its data while still being able to make accurate inferences about it.
Count-Min Sketch: Implementation
The Count-Min sketch supports two operations: and . returns the frequency count of , which is the number of times that has been invoked in the past.
Count-Min sketch has two parameters: the number of buckets , and the number of hash fucntions, . Given that , this compression leads to errors, and are also independent of the length of the array, . That data structure starts out as an by 2-D array of counters, all initially 0.
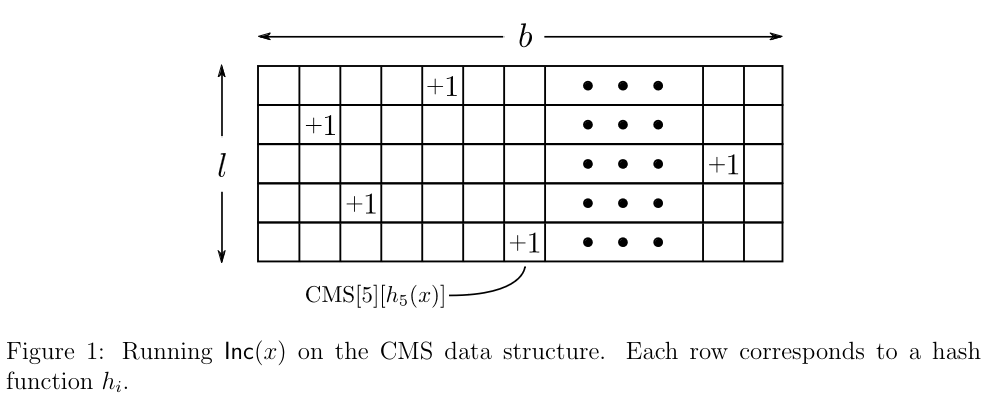
After choosing the hash functions , each mapping the universe of objects to , the code for is:
:
Increment
Assuming each hash function can be evaluated in constant time, the running time is , which is .
Choose a row . Since every time is called, the same counter is incremented, and never decremented, clearly:
where is the frequency count of . Thus, cannot underestimate , it overestimates it.
Since our estimates only suffer one-sided error, the smallest estimate is the best. Thus, is:
Errors are bounded to and .
Count-Min Sketch: Heuristic Error Analysis
To get an error rate around 1%, setting to 5 is good enough.
Solving the Approximate Heavy Hitters Problem
With the Count-Min Sketch, we can solve the approximate heavy hitters problem.
If we know the length, , then process the array elements using CMS in a single pass, and remember an element once its estimated frequency is .
If we don’t know the length, then we can store potential heavy hitters in a heap data structure. Keep a count of seen items, . When processing the next object of the array, invoke and then . If , then store in the heap, using the key . We also check to see if is greater than the minimum key in the heap. If so, we pop it, continuing onto subsequent elements if necessary.
Prev: introduction-consistent-hashing Next: similarity-search