Generalization
Prev: curse-of-dimensionality Next: regularization
Data Sets as Random Samples
There are two general modes when analyzing data sets:
- To deeply understand the peculiarities of a single dataset and say something meaningful about just that dataset.
- Using a dataset to extrapolate to additional data.
For example, when rolling out the Covid-19 Vaccine, you might use some randomized controlled trial to say something about the population at hand.
For example, for the COVID-19 Vaccine, of the 21,720 people who received the vaccine, 8 people got covid more than 7 days after the second dose. In comparison, of the 21,728 participants who received a placebo, 162 people got covid. We would like to take this data and generalize it throughout the population.
We’ll start off with the assumption that data points are random samples from some underlying population. There’s a lot of things to be careful of when assuming this in the real world, but we’ll assume all our samples follow this rule.
Another example might be classifying spam, from an intiial labeled dataset. We learn an algorithm on the dataset, and then let it out in the wild, to have it label more things as spam.
Binary Classification
There are many types of learning problems, but we’ll focus on Binary Classification problems, which involve the following.
- Data points correspond to points in -dimensional Euclidean space . For the spam problem, this would be different words that we’re keeping track of.
- There is a “ground truth” function specifying the correct classification of each datapoint (i.e. there is a mapping of every datapoint to true or false, and this never changes). The function f is unknown and is what we want to learn.
- There is an unknown distribution on . We can simplify as the uniform distribution over a very large finite subset of (like all emails with at most 10,000 unique characters).
Here’s the problem solved by a learning algorithm:
Input: data points , with each drawn i.i.d from the distribution , with a corresponding . The constitute the training data, where is labeled as either true or false.
Output: The responsibility of the learning algorithm is to create a prediction function .
Success criterion: the prediction function should be as close as possible to . It would look something like this, where we want our function to match the line drawn here, .
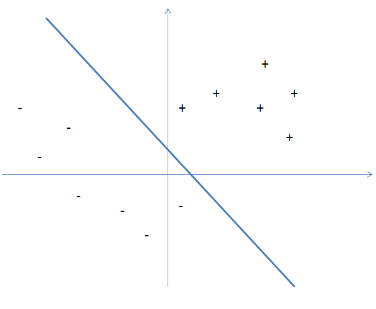
There are two more critical aspects of the learning problem:
- The amount of data. The more data you have, the closer you are to learning about the ground truth function .
- The number of possible functions that might be the truth. The fewer functions that you’re trying to distinguish between, the easier the learning problem.
Training Error and Generalization
The goodness of a prediction function can be assessed with the generalization error, the probability that g disagrees with the ground truth on the label of a random sample.
We can’t calculate the generalization error of a prediction function, because we don’t know nor the distribution . We do know points, and their ground truth labels, so we can grade based on that. This is called the training error of :
For any prediction function, its expected training error over the random sample is its generalization error. However, we don’t know if the training error of ona random sample is likely to be close to its generalization error — we don’t have enough data.
This can be phrased as “does g generalize?” and it depends on the algorithm and the size of the data.
For example, if a learning algorithm outputs a prediction function with generalization error much higher than its training error, it has overfit the training data. When a prediction function overfits its training data, it doesn’t say anything meaningful about the data.
Analysis: The Well-Separated Finite Case
Let’s start off with a simpler version of the learning problem with two assumptions:
-
(Finite) The ground truth function belongs to a known set of different functions. That is, there are only different possibilites for what might be, and we know the options up front.
-
(Well-separated) No function (other than ) is extremely close to , meaning that every candidate has generalization error of at least .
Our First Learning Algorithm
Our first learning algorithm to get 0% generalization error is to output the following function:
Thus, it has 0% training error. We don’t know if it generalizes, because we don’t know how large our should be.
Getting Tricked by a Single Function
We want to avoid getting tricked, that is, generating a function that is different from the true . We’re concerned about getting tricked by , meaning that it winds up having 0% training error, despite it having a generalization error .
The probability of that is:
Which is .
So the probability is decreasing exponentially with the number of samples .
The Union Bound
The union bound says that for events ,
Basically, this says that at least one of the events occurring is bound by the minimum of the less likely event.
In most applications, the events are bad events that we don’t want to happen. The union bound says that as long as each event occurs with low probability and there aren’t too many events, then with high probability, none of them occur.
Completing the Analysis
Let denote that an incorrect function has 0% training error on samples, despite having generalization error at least . Since there are such values of , the union bound implies that this probability is:
Pr_{x_1,\dots,x_n \sim D}[\text{some }f_j \ne f \text{ has 0% training error}] \le \displaystyle \sum{j = 1}^h e^-en = h * e^-en
We can simplify this to , so is an upper bound on the failure probability of the learning algorithm. The upper bound increase linearly with the number of possible functions, but decreases exponentially with the size of the training set.
So, if we wanted some , we set and solve for :
With probability of , the output of the learning algorithm is the ground truth function .
So, generalization error is linear (to reduce it from 10% to 1% requires 10x more data), but is logarithmic, so setting the to be very small, with large ‘s isn’t a problem.
PAC Guarantees: The Finite Case
Suppose we loosen the second argument, that there are no functions close to , the ground truth function. We now might output this other function , but if it’s similar enough to , it should be fine. We can use the same logic, with the stipulation that the output of the learning function has a generalization error less than .
This is a PAC guarantee, which is “probably approximately correct”.
PAC Guarantees: Linear Classifiers
Now we loosen the first assumption, but with a caveat — that the ground truth function has some structure. If is unrestricted, from to , then the unseen points could be anything, and the learning algorithm could not meaningfully say anything about it.
Linear Classifiers
A linear classifier in is specified by a -vector of real coefficients, and is defined as the function :
A lienar classifier in dimensions has degrees of freedom.
From the Curse of Dimensionality to Generalization
The curse of dimensionality can be used for a positive result here. Since the number of distinct directions in grows exponentially with , since the complexity of generalization grows logarthmically to the number of functions, then there is a complexity of learning a good classifier which is linear to , which is true.
We use the same theorem:
Where c is a sufficiently large constant. The output of the learning algorithm is a linear classifier with generalization error less than .
A Rule of Thumb
If , then prediction functions tend to generalize. If , then they do not.
FAQ
Three questions are:
- How do we implement the learning algorithm?
- What if no function has 0% training error?
- What happens if ?
The next two sections answer the first and second question.
Computational Considerations
The learning algorithm can be implemented in a few ways. If there are a finite number of candidates, then exhaustive search works. But for infinitely many linear classifiers, that won’t work.
One way is to use linear programming, or to use iterative methods like stochastic gradient descent, perceptron, etc.
Non-Zero Training Error and the ERM Algorithm
If the ground truth is not a linear function, we have to extend the learning algorithm somehow.
Generalization Guarantees for the ERM Algorithm
Empirical Risk Minimization (ERM): Output the function (from the set of functions under consideration) that has the smallest training error, breaking ties arbitrarily.
This has a PAC guarantee like the basic learning algorithm, with larger sample complexity.
Sample Complexity Considerations
Since the ERM algorithm has a worse complexity bound by a factor of $\frac{1}{e}, it is NP-hard, and we require heuristics.
Prev: curse-of-dimensionality Next: regularization